

哈希游戏平台散列 hasing
哈希游戏作为一种新兴的区块链应用,它巧妙地结合了加密技术与娱乐,为玩家提供了全新的体验。万达哈希平台凭借其独特的彩票玩法和创新的哈希算法,公平公正-方便快捷!万达哈希,哈希游戏平台,哈希娱乐,哈希游戏散列,又称哈希(Hash),是把任意长度的输入(又叫映射),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射。
如果数组hashTable有10000个元素,则每个元素都对应于或映射到hashTable中唯一的一个元素,该元素引用相应的对象,则这是理想散列。
完美的散列函数将每个查找键映射为不同整数,以该整数作为散列表的索引正合适。
但是绝大多数的散列表却不满,甚至是稀疏的,即仅有少量元素被实际用到。对于数组10000个元素如果一对一映射,则浪费了分配给这个散列表绝大部分的空间,如果只有700个元素且不是连续的,则需要一个更小的散列表。
给定一个非负整数i与一个含有n个位置的散列表,i对n取模的值得范围从0到n-1。即i对n的模就是i除以n的整数余,则这个值就是散列表的合法索引。
查找键往往不是整数,而是字符串。因此,散列函数首先要将查找键转换为一个整数散列码,然后将这个整数转换为一个作为特定的散列表的索引。
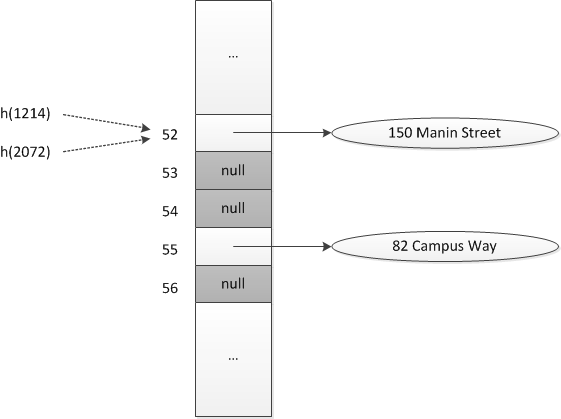
由于10000个元素映射到tableSize个索引,则某些元素被映射到相同的索引,这一现象称为冲突。
典型的散列函数不是完美的,因为他们可以允许不止一个查找键映射到同一个索引,导致散列表的冲突。
Java的基类Object有一个方法hashCode返回一个整数散列码。这个默认的散列码通常不适合用于散列,因为他对于两个相等的对象将有不同的散列码。为了对词典之类的实现有用,散列码必须将相等的对象映射到散列表中的相同位置。
如果equals方法认为这个对象相等,则hashCode对这两个对象必须返回相同的值;
如果在程序执行过程中,一个对象不止一次调用hashCode,并且如果在这段时间内对象的数据保持不变,则hashCode必须返回相同的散列码;
查找键常常是字符串,由一个字符串产生一个号的散列码是很重要的。首先为字符串中的每个字符分配一个整数(1-26是字符A-Z,27-52是a-z),然而使用字符的Unicode整数更常见。
更好的字符串散列码是由将每个字符的Unicode值乘以一个基于该字符在字符串中位置的因子。即散列码是这乘积之和。
如果查找键的数据类型是int,可以用查找键本身作为散列码。如果查找键是byte、short或char的实例,可以将它们类型装换为int以得到散列码。
对于其他基本类型,可以利用他们内部二进制表示。如查找键是long类型的整数,则它是64位,int是32位的,将64位转换为int,将丢失它的前32位,会造成所有只在前32位不同的查找键将具有相同的散列码从而发生冲突。
代替忽略long类型的查找键一部分的做法,将它分成若干部分,然后在使用加法或者像异或这样的按位布尔运算将这些部分结合起来,这个过程叫做折叠。例如将一个long查找键分为32位的两半,为了得到左半部分,将查找键向右平移若干位。
缩放一个整数使之位于给定取值范围内的最常见的方法是取模计算,即Java的%运算符。对于正的散列码c与正整数n,c%n取余作为结果,这个余数在0到n-1之间。
由于c的奇偶性,但基于内存地址的散列码通常是偶数,所以如果n是偶数就将漏掉散列表中许多为位置的索引。因此散列表长度n只能是奇数。
散列码的长度应该是素数n(一个只能被1和它本身整除的数,除2之外的素数都是奇数),则如果使用c%n将正的散列码c压缩为索引,索引将在0到n-1之间均匀分布。
在词典中插入元素时,如果散列函数将一个查找键映射到散列表中一个已使用的位置,则需要为这个查找键相关联的值寻找另一个位置。有两种方法:
在散列表插入元素的过程中发生冲突时,开放定址模式在散列表中寻找另一个代替的可用或开放位置,然后用这个位置引用新元素。
在散列表中寻找开放位置称为探测(probing),在线性探测中,如果发生冲突在hashTable[k],就检查hashTable[k+1]是否可用,如果不可用就检查hashTable[k+2],以此类推,这些冲突的散列表位置构成了探测序列,如果探测序列达到了散列表末尾,再从散列表的起始位置继续查找。
线性探测通过从初始位置的散列索引开始检查散列表中连续位置,并寻找下一个可用位置,已解决散列过程中的冲突。

线性探测可以检查散列表的每个位置。因此只要散列表不是满的,这种探测可以确保add操作的成功。
对与给定查找键所对应的元素的成功查找,将遵循与这个元素插入散列表时所用相同的探测序列。
虽然散列表中在从未使用过的位置应该终止查找,但在已用过且现在可重新使用的位置不应该终止查找。
为了检索一个元素,getValue(key)在探测序列中查找key,它检查现有的元素,忽略处于可用状态的位置,查找终止于key被找到时或遇到null时。
操作remove(key)使用与检索操作相同的逻辑查找序列,如果找到key,它将该位置标记为可用。
操作add(key, value)使用与检索操作类似的逻辑查找探测序列,但它也记录遇到的第一处/处于可用状态的位置的索引,如果key未找到,则使用这个位置放入新元素。
用线性探测处理冲突导致散列表中成组的连续位置被占据。每个组称为一个聚群,这种现象称为一次聚集。每个聚群是在插入、删除或检索一个元素时必须查找的一个探测序列。
当冲突较少时,探测序列保持较短并可被快速查找,但插入过程中的任何冲突都会增加聚群的长度。更大的聚群意味着冲突之后更长的查找时间。随着聚群的长度增加,可能合并为更大的聚群。
如果一个给定的查找键散列表到索引k,线性探测将查看从索引k开始的连续位置,二次探测则考虑索引k+
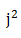

线性探测的优点是它能够探测到散列表中的每个位置,他保证散列表不满时add操作能成功。如果散列表最多半满,并且长度为素数,则二次探测可对add操作作同样的保证。
双散列使用第二个散列函数,以依赖于查找键的方式计算这些增量。因此,双散列既避免一次聚集又避免二次聚集。
处理冲突的第二种方法是修改散列表的结构,使得每个位置可以表示不止一个值,这样的位置称为桶(bucket)。使用由链表构成的桶处理冲出,称为链地址。
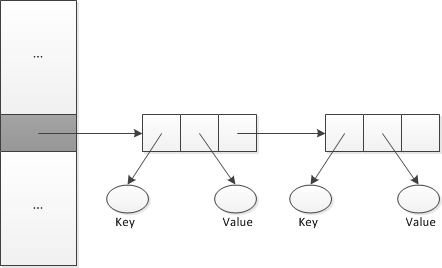
如果词典允许重复的查找键,则将新元素插入到相应的链表头,如果查找键不允许重复,则插入新元素要在链表中先查找,如果未找到,则位于链表末尾插入新元素。